


Vision and Knowledge. 'AICAP'
- Taylor H
- Dec 10, 2019
- 14 min read

"Whether used to report, analyse, compare, preserve, or persuade, photography has long been presented as furnishing us with 'facts'."
This project is essentially asking us to challenge the notion of objectivity in different photographic practices. There is a pre-existing core idea in many photographic practices that "seeing is believing", or visual representation being the truth. It is our job here to show that this is not the case, however it is rather the context that an image is produced that gives it it's meaning. Some examples of some photographic practices that are 'objective': Documentary, Survey, Scientific, Medical, Forensic, Anthropological, and Military.
This is a very interesting topic to me, because it calls the entire nature of photography into question. However, I don't want to do something that is too surface level here (e.g. Photoshop composites). I would like to achieve an obscure look, like something you wouldn't see everyday. Because of this though, I'm struggling to think of things to do.
My initial idea was to do with the medical side of things. I went with this because unlike any other practice, this is the only one with a reason not to hide the objective truth. The images produced have to show exactly what the deal is, because it could mean life or death for someone. Also, this area has machines other than cameras to make images, such as x-ray, or MRI. This is just a pipe dream though, because I don't think that I would be allowed access to these things, and I'm not committed enough to try and build my own. I do think however I can try and replicate the style of those images, because I could present them as what they are supposed to look like. For instance, I could do photograms, which sort of look like x-rays. If I were to fully commit to this idea, I could make broken bones out of splintered wood, and make a casting for a body part out of gelatin to produce a similar effect to that of an x-ray. I'm a little lost on how to replicate the MRI though.




Another thought I had was to do with Military, and a little bit of Conspiracy Theory as well. There have been several reports from US Airforce pilots that say that they have seen UFOs in the sky that don't move according to the laws of flight on earth. Everyone's first thoughts jumped to aliens, but upon closer analysis, it just turned out to be an error in the cameras installed or just visual artifacts in the plane's camera that looks like an object. This idea might not need to have anything to do with aliens or the military, but I enjoy the idea that I could use a camera's shortcomings to produce an image of something that isn't really there. I could circuitbend a cheap digital camera to short-circuit how the camera takes in information, or I could remove (or add my own) filters on the inside of the camera to also change how light is processed by the camera.


Needless to say, these are just base level ideas, and need to be fleshed out a lot more.
I found a lot of this work very intriguing, I especially enjoyed Trevor Paglen's work with artificial intelligences and neural networks to produce an image. I think that this fits the brief's theme quite well, because it calls into question who exactly is presenting the image. This body of work is from the point of view of the AI. Granted, it is sourcing its knowledge from images and text that humans have given it, but the final product is the AI's understanding of it all in visual form. This then breaks down the whole "seeing is believing" notion, because what is being shown hasn't ever been seen by anyone, except the AI. I would like to experiment around with a few neural networks or AIs to see how a machine can provide its own insight into the work, and make me look at things differently. I feel that an AI can add a layer of personality to the work, because what it is presenting is based on the experience that it has been given. Just like people I suppose.






I also enjoyed the simplicity of Liz Orton's work, and the way that it presents people from the viewpoint of machines. The equipment used in hospitals don't see us for who we are, but as things to be observed. As obvious as that sounds, to me it's quite curious that there is a disconnect between us and the equipment, unlike the relationship between a person and their camera. The photographs produced by these machines have absolutely no intent behind them to represent anything, or to push any meaning, they only serve to document, observe, and categorise the human body. I think that this could be an interesting theme to go forward with, especially paired with the whole AI thing.






I wanted to dive a little deeper into each of the artist's work, so I did more research online. I ended up finding a lot of information, but I particularly focused on an interview with Paglen, and an article about Orton because they both were fascinating to read through.
The interview with Trevor Paglen outlines several different ideas behind his work, what it all means, and his personal outlook on things. The interview begins by Paglen talking about how AI has a lot more human input than we think. They work by being fed hundreds of thousands of images taken by a human, and a human needs to label each input image with what is pictured so that the AI can tell what it is, and use that as a reference so it can distinguish that item in its surroundings. This means that there can be a bias to this AI, because the person training the AI could put whatever images in or omit whatever they want in order to reach what they want. Trevor leans into this subjectivity, making sets based on literature and metaphors. For instance, Paglen has a set called The Interpretation of Dreams. It goes through a Freud book about interpreting dreams, and familiarises itself with all of the symbols that Freud thinks are important for interpreting dreams, like injections, puffy faces, scabby throats, windows, or ballrooms. So for instance, if you show that AI a landscape, it won't see rolling hills, mountains, or rivers, it'll recognise what it was trained on instead. With these generative AIs, instead of asking it to recognise things in an image, you ask it to draw a picture of what it is trained on, essentially creating its own artwork based on its own experience. Trevor also talks of his inspiration from René Magritte. With his painting The Treachery of Images, we can read "This is not a pipe" and recognise that it is a painting of a pipe, whereas an AI is trained on a set of rules that it cannot break, so it literally cannot distinguish between a representation of an object and the actual object itself. One thing that I found particularly interesting in this interview was Paglen talking about his intentional blurriness in his earlier images. It doesn't have anything to do with his AI images, but it still rings true about all images. He said:
"I think of clarity and blurriness as almost epistemological genres. They do different kinds of work. When you see something that’s really clear, you imagine that you can understand it. Seeing something very blurry forces you to confront that you don’t really understand the thing".
I think that I would like to incorporate this ethos into my work here as well. (spoiler alert, I'm writing this after I've done a bunch of tests) I already know that the images aren't going to be very sharp, but that brings the notion of humanity's limited understanding of the world around us, and how we find it difficult to remove ourselves from our own perspective, and seeing things from other people's. Combined with the alienlike imagery, it'll create a confusing and perhaps disturbing effect in the work.
Inspired by Trevor Paglen's work, I set out to find as many AI image tools as I could. Luckily, I managed to find a few fairly quickly.
The first AI tool I properly looked into was called ArtBreeder, which uses AI to combine two images together. Sounds fairly simple and uninteresting, but when you look at the results you'll see why I immediately became fascinated.

I still wanted to lean into the alien side of things, so my first thought was to combine different animals to create an alien-like creature. I think that this could be worth looking into, because it dives into dealing with who is presenting the image, in this case it's an AI presenting what it thinks two images would look like mixed together based on what it's been fed already.
The way the site works: You are presented with six already generated images, and you are asked to pick the one you find most interesting. Once you've done that, another menu comes up, where you see a higher resolution version of the image, and six more sub-images with a slider which changes how similar or different they are to the base image. You can then save those images to your account, and go even further down the rabbit hole.



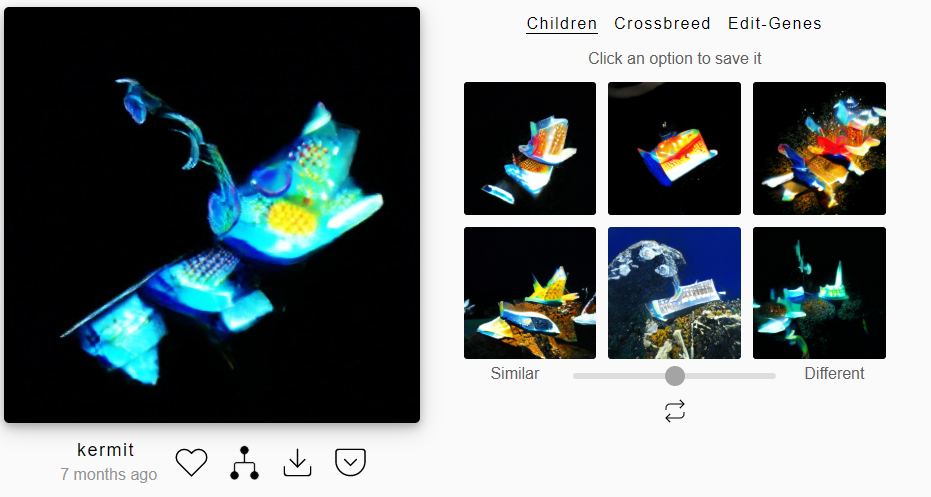




I spent a little while messing around with this site, and even came out with some images that I was happy with.












I love these images. It feels to me that the AI is presenting it's own objective truth, because it is being fed images by us, so it only spits out images that it thinks is real as well. It feels to me that this is a form of AI imagination. It's also similar thematically to Liz Orton's work, which deals with the way that machines view the body. To me, this deals with the way that Neural Networks view everything. The only gripe that I had with this site was that you could only use images provided with the site, so unfortunately I couldn't use my own prompts like I originally wanted. Annoyingly, they're working on that feature right now (alongside higher-res images rendering), but it will cost $8 a month. Maybe in future I might give it a look, it's worth giving these people the money for the work they're putting in to it, and it'll be interesting to see what the AI does with images it's never seen before.
As I delved further into different applications and tools I could use, I saw plenty of style changers; where it would take an input image, and a 'style' image, and it interprets the 'style' and applies it to the input image (see below for example). However, this wasn't the sort of image I wanted to create. I wanted a completely otherworldly image, but this takes an image and only changes the colours and textures.

The next application I found has been my favourite so far. It's a desktop application called Runway that has a whole plethora of different generative AIs, from text to image generators, to AI that tracks human motion. There was one Neural Network I was particularly interested in though, and it's name is BigBiGAN. Now I'm no expert on AI at all, and there weren't any layman descriptions of how it works, but from what I could gather, it learns without the world. It's trained on an ImageNet (an image database), and after a while it's outputs are frozen. Then, something called a linear classifier is trained on it's own outputs. To me, someone who hasn't got the tiniest instance of a clue what any of this means or how it works, it seems like what this neural network bases it's outputs on aren't images taken by a human, but a strange reconstruction of the image that it has been fed.
Paper on how BigBiGAN works: https://arxiv.org/pdf/1907.02544.pdf

I messed around with the AI a little bit, and I was instantly hooked. It asks you to input an image (for these tests I'm just using some disposable camera shots my friend took over the summer), and after a small wait it spits out an incredibly odd image.


^Before ^After
What seems strange to me is that the default way that it outputs an image is that it renders it in a square format, and 256x256 pixel resolution. I'm not sure why, but it still spits out an incredibly cursed image. Below are some more results that I got with this.












I love it. It's exactly what I was looking for, otherworldly images processed by a machine that only knows it's own hallucinations. I was still irked by the tiny image size however, but Runway has a remedy for this. Introducing AI Upscaling. It basically has two databases, one of high resolution images, and one of low resolution images. It then takes the high res images and determines what detail needs to go where, and applies those details to low res images. It's a lot more complicated than that and I've probably got a few things wrong, but all I know is that it takes a small image and makes it bigger while generating detail where there wasn't any before. There are two uspscalers on Runway, one called Image-Super-Resolution, and another called ESRGAN. I wanted to test them both, to see which one achieved the effect I wanted better. I tested them by running an output image from BigBiGAN through each one 2 or 3 times to achieve an image with a 2048x2048 resolution.

Image-Super-Resolution: I found this one to be great. From the one test image I used, it added a texture to everything, and instead of the fuzzy pixels from the original, it turned into a blotchy blurry effect that I find quite appealing, and fully leans into the 'blurriness creating confusion and forces the viewer to understand that they don't understand what the image is' idea. It still keeps it's blurry aesthetic, while creating a new texture in the image that wasn't there before. This is another instance of AI creating its own information that wasn't in the original, again calling the objectivity of these images into question.






ESRGAN: I found this one to be a lot worse. It seems to do things pixel by pixel, which makes the output image look the same as it did originally, just a lot bigger and with a bunch of artifacts. I could see how someone could find this interesting, but for the look that I'm going for it just doesn't work.




Overall, I'm pretty excited by these AI experiments. I 100% want to use this moving forward, I think that I can produce a very amazing body of work this way, and due to ISR (Image-Super-Resolution), I could get some decent prints as well. The only irritating thing with Runway is that they charge to use their drivers. In order to run these neural networks, we have to run them on the Runway servers, and obviously it costs to keep them up. You get a free five Australian dollar credit when you join, but as you use their AIs it slowly depletes. Hopefully I can drain as much as I can out of the $4.25 AUD I have left, but it seems that I'll have to fork over some cash if I want to use it long term.
I also went to a printing workshop, and I learnt a lot about colour matching and how to achieve the colours I want in an image. I used this experience as an opportunity to test out a print, to see what the quality was like. I'm fairly impressed with the print. It's kept the skinlike texture perfectly, and seeing it in physical form makes the image even more special. I only wanted to test the detail of the printer though, so I wasn't too fussed about the colours. However, when it comes to me actually printing, I will use the knowledge I attained at the workshop to get the exact colour that I want.
I think I have a final concept that I want to go with moving forward. Essentially, it's the child of Liz Orton and Trevor Paglen's work, staged as scientific research on us as humans. I want to take photographs of different body parts/people in different poses and what it will come out with will look like medically staged photographs of us. It deals with the theme of the AI presenting what it sees as opposed to what's actually there, and with the theme of the machine seeing us/everything as objects to be measured, observed, and documented, and it challenges the objectivity of medical and scientific research photography. I feel that this fits the brief perfectly, and it'll be very interesting to see how it comes out.
The first thing I need to do is take some photographs of some people. I also want to figure out which camera I want to use. On one hand, using a DSLR would be a nuisance because the program runs a lot slower with bigger images, it uses more server bandwidth meaning I can't do it as often without topping up credit, and it's all condensed down to a tiny square to be upscaled anyway. On the other hand, I'm not sure if it takes every bit of detail from all the megapixels and condenses it or not, so if there's more detail in the input image then the image could look quite different. A lower quality camera however, would come out with a less clear image, which could be more obscure, perhaps confusing the AI a little, wildly changing the output image.
The first shoot I did was some close ups of my face. I thought that this would be a great idea to start out with, as it gives a more personal feeling to the project, even if the end product doesn't resemble me at all. Plus I think that making it my own face allows the work to become a sort of 'Anti-Self Portrait'.
The photos I used were taken with a DSLR, and I'm very happy about how they turned out. I was very surprised to see that BigBiGan can recognise faces, replacing my identity with a false one. Unfortunately, I didn't write down which photograph I used for each AI image, so each piece remains a mystery as to what it is. All photographs used were of my eyes, nose, mouth, teeth, and overall face. I ran each image through BigBiGAN, and through the Image Super Resolution AI a couple of times to make the size of the image much bigger. Below is a gallery containing all of my favourite pieces.
























I also did a little research on why artists produce self portraits and the theory behind it, and I came across something that resonated with me and the work I'm making currently.
There are often photographers that attempt to obscure themselves or pretend to be something they're not in order to negate the self. For example, I am using the filter of what the AI sees in the photographs I feed it to hide away the structure and features that make up my identity. Similarly, contemporary artist ORLAN produced work involving several plastic surgeries in order to "re-invent" herself. This work challenges the idea of where we place identity within ourselves. Through this body of work I learned that it doesn't matter how much we change and distort our appearance, our identity is trapped within us as it is a representation of us as a conscious entity. Basically, any representation of self created by a conscious being can be classed as a self-portrait.

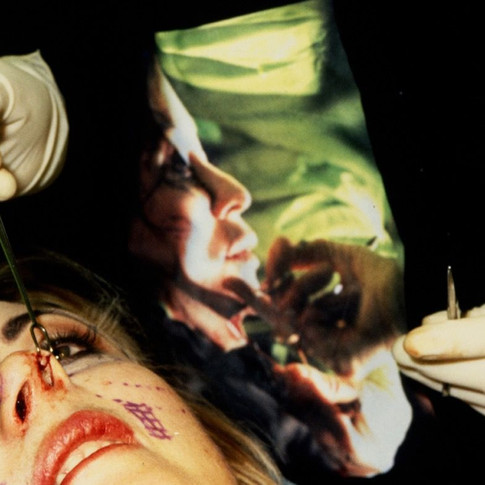


But what happens if something that isn't conscious produces the portrait? It would be like having my identity stripped away from the self portraiture by viewing it from the eyes of the AI. No gender, race, class, culture, or sexual orientation on display here, just raw representation. It takes away my story, my friends, my family, and my appearance. The images produced will have nothing to do with me visibly, and because I'm not the one representing myself, it won't have anything to do with me practically. It reminds me a lot of colonialist photography, where people would invade other countries and document the people that already occupy that country by lining them up in front of a grid background. This took away the people's identity as it transformed them into objects to be measured.






However, the only difference here is that I am giving the AI consent to strip this identity away from me, whereas with colonialism it was forced upon them. This self imposed other-ing allows me to view myself through the eyes of AI, which in turn allows me to view myself without identity and without personality. An AI Ego Death, if you will.
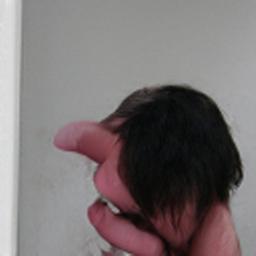
I also did a few experiments with my hands, and the results were interesting and body horror-ish, however I feel as if the photos of my face have more to do with my identity, so I think I will stick with the facial images. Also, for whatever reason, they have removed the Image Super Resolution GAN between when I used it last and now, so producing the same upscaled aesthetic that we achieved before will be impossible.




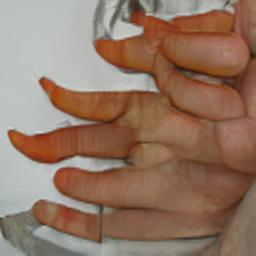







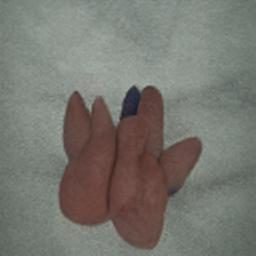


Overall, I think that this project went brilliantly. I found researching areas of photography that claim to function objectively quite stimulating, and finding ways to twist them into different things was fun as well. I also found working with AI an interesting and fruitful new avenue to go down (perhaps in future as well), and I never would have considered it without Paglen as inspiration. I also enjoyed working with different AIs and seeing what comes out of them. I have decided to title this work 'AICAP', which stands for Artificial Intelligence Colonialist Anti Portraiture. I think that this name is appropriate because (obviously) it works with artificial intelligence, I framed the work as AI performing its own research as a sort of cyber-colonialist photography, and the anti portraiture part is inspired by the lack of consciousness that was required to produce the images, and the transformation from Self Portrait to Portrait when switching over authorship when it comes to image production. The abbreviation AICAP also leaves the series open for future additions in case I would like to work in this area again.
I think that there are a few areas for improvement. For example, I would like to do further shoots, maybe with other people, or body parts. I could work with body shape rather than identity, or maybe I could work with other ways of representing identity, like living space or communities instead. That's the beauty of leaving this series open ended though, I can come back to it whenever I like.























Comments